
BASE DE DATOS

Una base de datos o banco de datos es un conjunto de datos pertenecientes a un mismo contexto y almacenados sistemáticamente para su posterior uso. En este sentido, una biblioteca puede considerarse una base de datos compuesta en su mayoría por documentos y textos impresos en papel e indexados para su consulta. Actualmente, y debido al desarrollo tecnológico de campos como la informática y la electrónica, la mayoría de las bases de datos están en formato digital (electrónico), y por ende se ha desarrollado y se ofrece un amplio rango de soluciones al problema del almacenamiento de datos.
Existen programas denominados sistemas gestores de bases de datos, abreviado SGBD, que permiten almacenar y posteriormente acceder a los datos de forma rápida y estructurada. Las propiedades de estos SGBD, así como su utilización y administración, se estudian dentro del ámbito de la informática.
Las aplicaciones más usuales son para la gestión de empresas e instituciones públicas. También son ampliamente utilizadas en entornos científicos con el objeto de almacenar la información experimental.
Aunque las bases de datos pueden contener muchos tipos de datos, algunos de ellos se encuentran protegidos por las leyes de varios países.
Tipos de Base de Datos
Las bases de datos pueden clasificarse de varias maneras, de acuerdo al contexto que se esté manejando, la utilidad de las mismas o las necesidades que satisfagan.
Según la variabilidad de los datos almacenados
Bases de datos estáticas
Son bases de datos de sólo lectura, utilizadas primordialmente para almacenar datos históricos que posteriormente se pueden utilizar para estudiar el comportamiento de un conjunto de datos a través del tiempo, realizar proyecciones, tomar decisiones y realizar análisis de datos para inteligencia empresarial.
Bases de datos dinámicas
Éstas son bases de datos donde la información almacenada se modifica con el tiempo, permitiendo operaciones como actualización, borrado y adición de datos, además de las operaciones fundamentales de consulta. Un ejemplo de esto puede ser la base de datos utilizada en un sistema de información de un supermercado, una farmacia, un videoclub o una empresa.
Según el contenido
Bases de datos bibliográficas
Sólo contienen un subrogante (representante) de la fuente primaria, que permite localizarla. Un registro típico de una base de datos bibliográfica contiene información sobre el autor, fecha de publicación, editorial, título, edición, de una determinada publicación, etc. Puede contener un resumen o extracto de la publicación original, pero nunca el texto completo, porque si no, estaríamos en presencia de una base de datos a texto completo (o de fuentes primarias —ver más abajo). Como su nombre lo indica, el contenido son cifras o números. Por ejemplo, una colección de resultados de análisis de laboratorio, entre otras.
Bases de datos de texto completo
Almacenan las fuentes primarias, como por ejemplo, todo el contenido de todas las ediciones de una colección de revistas científicas.
Directorios
Un ejemplo son las guías telefónicas en formato electrónico.
Bases de datos o "bibliotecas" de información química o biológica
Son bases de datos que almacenan diferentes tipos de información proveniente de la química, las ciencias de la vida o médicas. Se pueden considerar en varios subtipos:
- Las que almacenan secuencias de nucleótidos o proteínas.
- Las bases de datos de rutas metabólicas.
- Bases de datos de estructura, comprende los registros de datos experimentales sobre estructuras 3D de biomoléculas-
- Bases de datos clínicas.
- Bases de datos bibliográficas (biológicas, químicas, médicas y de otros campos): PubChem, Medline, EBSCOhost.
Modelos de Base de Datos
Además de la clasificación por la función de las bases de datos, éstas también se pueden clasificar de acuerdo a su modelo de administración de datos.
Un modelo de datos es básicamente una "descripción" de algo conocido como contenedor de datos (algo en donde se guarda la información), así como de los métodos para almacenar y recuperar información de esos contenedores. Los modelos de datos no son cosas físicas: son abstracciones que permiten la implementación de un sistema eficiente de base de datos; por lo general se refieren a algoritmos, y conceptos matemáticos.
Algunos modelos con frecuencia utilizados en las bases de datos:
Bases de datos jerárquicas
En este modelo los datos se organizan en una forma similar a un árbol (visto al revés), en donde un nodo padre de información puede tener varios hijos. El nodo que no tiene padres es llamadoraíz, y a los nodos que no tienen hijos se los conoce como hojas.
Las bases de datos jerárquicas son especialmente útiles en el caso de aplicaciones que manejan un gran volumen de información y datos muy compartidos permitiendo crear estructuras estables y de gran rendimiento.
Una de las principales limitaciones de este modelo es su incapacidad de representar eficientemente la redundancia de datos.
Base de datos de red
Éste es un modelo ligeramente distinto del jerárquico; su diferencia fundamental es la modificación del concepto de nodo: se permite que un mismo nodo tenga varios padres (posibilidad no permitida en el modelo jerárquico).
Fue una gran mejora con respecto al modelo jerárquico, ya que ofrecía una solución eficiente al problema de redundancia de datos; pero, aun así, la dificultad que significa administrar la información en una base de datos de red ha significado que sea un modelo utilizado en su mayoría por programadores más que por usuarios finales.
Bases de datos transaccionales
Son bases de datos cuyo único fin es el envío y recepción de datos a grandes velocidades, estas bases son muy poco comunes y están dirigidas por lo general al entorno de análisis de calidad, datos de producción e industrial, es importante entender que su fin único es recolectar y recuperar los datos a la mayor velocidad posible, por lo tanto la redundancia y duplicación de información no es un problema como con las demás bases de datos, por lo general para poderlas aprovechar al máximo permiten algún tipo de conectividad a bases de datos relacionales.
Un ejemplo habitual de transacción es el traspaso de una cantidad de dinero entre cuentas bancarias. Normalmente se realiza mediante dos operaciones distintas, una en la que se decrementa el saldo de la cuenta origen y otra en la que incrementamos el saldo de la cuenta destino. Para garantizar la atomicidad del sistema (es decir, para que no aparezca o desaparezca dinero), las dos operaciones deben ser atómicas, es decir, el sistema debe garantizar que, bajo cualquier circunstancia (incluso una caída del sistema), el resultado final es que, o bien se han realizado las dos operaciones, o bien no se ha realizado ninguna.
Bases de datos relacionales
Éste es el modelo utilizado en la actualidad para modelar problemas reales y administrar datos dinámicamente. Tras ser postulados sus fundamentos en 1970 por Edgar Frank Codd, de los laboratorios IBM en San José (California), no tardó en consolidarse como un nuevo paradigma en los modelos de base de datos. Su idea fundamental es el uso de "relaciones". Estas relaciones podrían considerarse en forma lógica como conjuntos de datos llamados "tuplas". Pese a que ésta es la teoría de las bases de datos relacionales creadas por Codd, la mayoría de las veces se conceptualiza de una manera más fácil de imaginar. Esto es pensando en cada relación como si fuese una tabla que está compuesta por registros (las filas de una tabla), que representarían las tuplas, y campos (las columnas de una tabla).
En este modelo, el lugar y la forma en que se almacenen los datos no tienen relevancia (a diferencia de otros modelos como el jerárquico y el de red). Esto tiene la considerable ventaja de que es más fácil de entender y de utilizar para un usuario esporádico de la base de datos. La información puede ser recuperada o almacenada mediante "consultas" que ofrecen una amplia flexibilidad y poder para administrar la información.
El lenguaje más habitual para construir las consultas a bases de datos relacionales es SQL, Structured Query Language o Lenguaje Estructurado de Consultas, un estándar implementado por los principales motores o sistemas de gestión de bases de datos relacionales.
Durante su diseño, una base de datos relacional pasa por un proceso al que se le conoce como normalización de una base de datos.
Durante los años 80 la aparición de dBASE produjo una revolución en los lenguajes de programación y sistemas de administración de datos. Aunque nunca debe olvidarse que dBase no utilizaba SQL como lenguaje base para su gestión.
Bases de datos multidimensionales
Son bases de datos ideadas para desarrollar aplicaciones muy concretas, como creación de Cubos OLAP. Básicamente no se diferencian demasiado de las bases de datos relacionales (una tabla en una base de datos relacional podría serlo también en una base de datos multidimensional), la diferencia está más bien a nivel conceptual; en las bases de datos multidimensionales los campos o atributos de una tabla pueden ser de dos tipos, o bien representan dimensiones de la tabla, o bien representan métricas que se desean estudiar.
Bases de datos orientadas a objetos
Este modelo, bastante reciente, y propio de los modelos informáticos orientados a objetos, trata de almacenar en la base de datos los objetos completos (estado y comportamiento).
Una base de datos orientada a objetos es una base de datos que incorpora todos los conceptos importantes del paradigma de objetos:
- Encapsulación - Propiedad que permite ocultar la información al resto de los objetos, impidiendo así accesos incorrectos o conflictos.
- Herencia - Propiedad a través de la cual los objetos heredan comportamiento dentro de una jerarquía de clases.
- Polimorfismo - Propiedad de una operación mediante la cual puede ser aplicada a distintos tipos de objetos.
En bases de datos orientadas a objetos, los usuarios pueden definir operaciones sobre los datos como parte de la definición de la base de datos. Una operación (llamada función) se especifica en dos partes. La interfaz (o signatura) de una operación incluye el nombre de la operación y los tipos de datos de sus argumentos (o parámetros). La implementación (o método) de la operación se especifica separadamente y puede modificarse sin afectar la interfaz. Los programas de aplicación de los usuarios pueden operar sobre los datos invocando a dichas operaciones a través de sus nombres y argumentos, sea cual sea la forma en la que se han implementado. Esto podría denominarse independencia entre programas y operaciones.
SQL:2003, es el estándar de SQL92 ampliado, soporta los conceptos orientados a objetos y mantiene la compatibilidad con SQL92.
Bases de datos documentales
Permiten la indexación a texto completo, y en líneas generales realizar búsquedas más potentes. Tesaurus es un sistema de índices optimizado para este tipo de bases de datos.
Bases de datos deductivas
Un sistema de base de datos deductiva, es un sistema de base de datos pero con la diferencia de que permite hacer deducciones a través de inferencias. Se basa principalmente en reglas y hechos que son almacenados en la base de datos. Las bases de datos deductivas son también llamadas bases de datos lógicas, a raíz de que se basa en lógica matemática. Este tipo de base de datos surge debido a las limitaciones de la Base de Datos Relacional de responder a consultas recursivas y de deducir relaciones indirectas de los datos almacenados en la base de datos.
Lenguaje
Utiliza un subconjunto del lenguaje Prolog llamado Datalog el cual es declarativo y permite al ordenador hacer deducciones para contestar a consultas basándose en los hechos y reglas almacenados.
Ventajas
- Uso de reglas lógicas para expresar las consultas.
- Permite responder consultas recursivas.
- Cuenta con negaciones estratificadas
- Capacidad de obtener nueva información a través de la ya almacenada en la base de datos mediante inferencia.
- Uso de algoritmos de optimización de consultas.
- Soporta objetos y conjuntos complejos.
Desventajas
- Crear procedimientos eficaces de deducción para evitar caer en bucles infinitos.
- Encontrar criterios que decidan la utilización de una ley como regla de deducción.
- Replantear las convenciones habituales de la base de datos.
Fases
- Fase de Interrogación: se encarga de buscar en la base de datos informaciones deducibles implícitas. Las reglas de esta fase se denominan reglas de derivación.
- Fase de Modificación: se encarga de añadir a la base de datos nuevas informaciones deducibles. Las reglas de esta fase se denominan reglas de generación.
Interpretación
Encontramos dos teorías de interpretación de las bases de datos deductiva consideramos las reglas y los hechos como axiomas. Los hechos son axiomas base que se consideran como verdaderos y no contienen variables. Las reglas son axiomas deductivos ya que se utilizan para deducir nuevos hechos.
- Teoría de Modelos: una interpretación es llamada modelo cuando para un conjunto específico de reglas, éstas se cumplen siempre para esa interpretación. Consiste en asignar a un predicado todas las combinaciones de valores y argumentos de un dominio de valores constantes dado. A continuación se debe verificar si ese predicado es verdadero o falso.
Mecanismos
Existen dos mecanismos de inferencia:
- Ascendente: donde se parte de los hechos y se obtiene nuevos aplicando reglas de inferencia.
- Descendente: donde se parte del predicado (objetivo de la consulta realizada) e intenta encontrar similitudes entre las variables que nos lleven a hechos correctos almacenados en la base de datos.
Sistema de Gestión de bases de datos distribuida (SGBD)
La base de datos y el software SGBD pueden estar distribuidos en múltiples sitios conectados por una red. Hay de dos tipos:
1. Distribuidos homogéneos: utilizan el mismo SGBD en múltiples sitios.
2. Distribuidos heterogéneos: Da lugar a los SGBD federados o sistemas multibase de datos en los que los SGBD participantes tienen cierto grado de autonomía local y tienen acceso a varias bases de datos autónomas preexistentes almacenados en los SGBD, muchos de estos emplean una arquitectura cliente-servidor.
Estas surgen debido a la existencia física de organismos descentralizados. Esto les da la capacidad de unir las bases de datos de cada localidad y acceder así a distintas universidades, sucursales de tiendas, etcétera.
Sistema de Gestion de Base de Datos
Objetivos
Existen distintos objetivos que deben cumplir los SGBD:
- Abstracción de la información. Los SGBD ahorran a los usuarios detalles acerca del almacenamiento físico de los datos. Da lo mismo si una base de datos ocupa uno o cientos de archivos, este hecho se hace transparente al usuario. Así, se definen varios niveles de abstracción. Nótese que si la base de datos es pequeña, la misma podrá ser ubicada sin dificultades en un mismo volumen de memoria e incluso en un mismo archivo; obviamente las cosas se complican si la base de datos es enorme, y si además los registros individuales de información tienen muchos diferentes datos con una estructura entre ellos más o menos compleja.
- Independencia. La independencia de los datos consiste en la capacidad de modificar el esquema (físico o lógico) de una base de datos, sin tener que realizar cambios en las aplicaciones que se sirven de ella.
- Consistencia. En aquellos casos en los que no se ha logrado eliminar la redundancia, será necesario vigilar que aquella información que aparece repetida se actualice de forma coherente, es decir, que todos los datos repetidos se actualicen de forma simultánea. Por otra parte, la base de datos representa una realidad determinada que tiene determinadas condiciones, por ejemplo que los menores de edad no pueden tener licencia de conducir. El sistema no debería aceptar datos de un conductor menor de edad. En los SGBD existen herramientas que facilitan la programación de este tipo de condicionantes.
- Seguridad. La información almacenada en una base de datos puede llegar a tener un gran valor. Los SGBD deben garantizar que esta información se encuentra segura de permisos a usuarios y grupos de usuarios, que permiten otorgar diversas categorías de permisos.
- Manejo de transacciones. Una transacción es un programa que se ejecuta como una sola operación. Esto quiere decir que luego de una ejecución en la que se produce una falla es el mismo que se obtendría si el programa no se hubiera ejecutado. Los SGBD proveen mecanismos para programar las modificaciones de los datos de una forma mucho más simple que si no se dispusiera de ellos.
Ventajas
- Proveen facilidades para la manipulación de grandes volúmenes de datos . Entre éstas:
- Simplifican la programación de equipos de consistencia.
- Manejando las políticas de respaldo adecuadas, garantizan que los cambios de la base serán siempre consistentes sin importar si hay errores correctamente, etc.
- Organizan los datos con un impacto mínimo en el código de los programas.
- Disminuyen drásticamente los tiempos de desarrollo y aumentan la calidad del sistema desarrollado si son bien explotados por los desarrolladores.
- Usualmente, proveen interfaces y lenguajes de consulta que simplifican la recuperación de los datos.
Inconvenientes
- Típicamente, es necesario disponer de una o más personas que administren la base de datos, de la misma forma en que suele ser necesario en instalaciones de cierto porte disponer de una o más personas que administren los sistemas operativos. Esto puede llegar a incrementar los costos de operación en una empresa. Sin embargo hay que balancear este aspecto con la calidad y confiabilidad del sistema que se obtiene.
- Si se tienen muy pocos datos que son usados por un único usuario por vez y no hay que realizar consultas complejas sobre esos datos, entonces es posible que sea mejor usar una hoja de cálculo en vez de un sistema de gestión de bases de datos.
- Complejidad: los software muy complejos y las personas que vayan a usarlo deben tener conocimiento de las funcionalidades del mismo para poder aprovecharlo al máximo.
- Tamaño: la complejidad y la gran cantidad de funciones que tienen, hacen que sea un software de gran tamaño, que requiere de gran cantidad de memoria para poder correr.
- Coste del hardware adicional: los requisitos de hardware para correr un SGBD por lo general son relativamente altos, por lo que estos equipos pueden llegar a costar gran cantidad de dinero.
- Lenguajes especializados: por más que el sistema de gestión de la base de datos sea eficiente y relativamente claro en cuanto a su uso, las cosas ciertamente se pueden complejizar cuando la diversidad de los datos y de los cambios a través del tiempo sean muy dinámicos; en estos casos muy posiblemente la interface entre el usuario y el sistema ya no convenga que se base en comandos sino en un verdadero lenguaje; a este respecto posiblemente convenga por ejemplo tener en cuenta a GeneXus.
Modelo Relacional
El modelo relacional para la gestión de una base de datos es un modelo de datos basado en la lógica de predicados y en la teoría de conjuntos. Es el modelo más utilizado en la actualidad para modelar problemas reales y administrar datos dinámicamente. Tras ser postuladas sus bases en 1970 por Edgar Frank Codd, de los laboratorios IBM en San José (California), no tardó en consolidarse como un nuevo paradigma en los modelos de base de datos.
Su idea fundamental es el uso de «relaciones». Estas relaciones podrían considerarse en forma lógica como conjuntos de datos llamados «tuplas». Pese a que ésta es la teoría de las bases de datos relacionales creadas por Edgar Frank Codd, la mayoría de las veces se conceptualiza de una manera más fácil de imaginar, esto es, pensando en cada relación como si fuese una tabla que está compuesta por registros (cada fila de la tabla sería un registro o tupla), y columnas (también llamadas campos).
En este modelo todos los datos son almacenados en relaciones, y como cada relación es un conjunto de datos, el orden en el que éstos se almacenen no tiene relevancia (a diferencia de otros modelos como el jerárquico y el de red). Esto tiene la considerable ventaja de que es más fácil de entender y de utilizar por un usuario no experto. La información puede ser recuperada o almacenada por medio de consultas que ofrecen una amplia flexibilidad y poder para administrar la información.
Este modelo considera la base de datos como una colección de relaciones. De manera simple, una relación representa una tabla que no es más que un conjunto de filas, cada fila es un conjunto de campos y cada campo representa un valor que interpretado describe el mundo real. Cada fila también se puede denominar tupla o registro y a cada columna también se le puede llamar campo o atributo.
Para manipular la información utilizamos un lenguaje relacional, actualmente se cuenta con dos lenguajes formales el Álgebra relacional y el Cálculo relacional. El Álgebra relacional permite describir la forma de realizar una consulta, en cambio, el Cálculo relacional sólo indica lo que se desea devolver.
Esquema
Un esquema es la definición de una estructura (generalmente relaciones o tablas de una base de datos), es decir, determina la identidad de la relación y que tipo de información podrá ser almacenada dentro de ella; en otras palabras, el esquema son los metadatos de la relación. Todo esquema constará de:
- Nombre de la relación (su identificador).
- Nombre de los atributos (o campos) de la relación y sus dominios; el dominio de un atributo o campo define los valores permitidos para el mismo, es equivalente al tipo de dato por ejemplocharacter, integer, date, string, etc.
Instancias
Una instancia de manera formal es la aplicación de un esquema a un conjunto finito de datos. En palabras no tan técnicas, se puede definir como el contenido de una tabla en un momento dado, pero también es valido referirnos a una instancia cuando trabajamos o mostramos únicamente un subconjunto de la información contenida en una relación o tabla, como por ejemplo:
- Ciertos caracteres y números (una sola columna de una sola fila).
- Algunas o todas las filas con todas o algunas columnas
- Cada fila es una tupla. El número de filas es llamado cardinalidad.
- El número de columnas es llamado aridad o grado.
Base de Datos Relacional
Una base de datos relacional es un conjunto de una o más tablas estructuradas en registros (líneas) y campos (columnas), que se vinculan entre sí por un campo en común, en ambos casos posee las mismas características como por ejemplo el nombre de campo, tipo y longitud; a este campo generalmente se le denomina ID, identificador o clave. A esta manera de construir bases de datos se le denomina modelo relacional.
Estrictamente hablando el término se refiere a una colección específica de datos pero a menudo se le usa, en forma errónea como sinónimo del software usado para gestionar esa colección de datos. Ese software se conoce como SGBD (sistema gestor de base de datos) relacional o RDBMS (del inglés relational database management system).
Las bases de datos relacionales pasan por un proceso al que se le conoce como normalización de una base de datos, el cual es entendido como el proceso necesario para que una base de datos sea utilizada de manera óptima.
Entre las ventajas de este modelo están:
- Garantiza herramientas para evitar la duplicidad de registros, a través de campos claves o llaves.
- Garantiza la integridad referencial: Así al eliminar un registro elimina todos los registros relacionados dependientes.
- Favorece la normalización por ser más comprensible y aplicable.
Normalizacion de Bases de Datos
El proceso de normalización de bases de datos consiste en aplicar una serie de reglas a las relaciones obtenidas tras el paso del modelo entidad-relación al modelo relacional.
Las bases de datos relacionales se normalizan para:
- Evitar la redundancia de los datos.
- Evitar problemas de actualización de los datos en las tablas.
- Proteger la integridad de los datos.
En el modelo relacional es frecuente llamar tabla a una relación, aunque para que una tabla sea considerada como una relación tiene que cumplir con algunas restricciones:
- Cada tabla debe tener su nombre único.
- No puede haber dos filas iguales. No se permiten los duplicados.
- Todos los datos en una columna deben ser del mismo tipo.
Terminologia equivalente
- Relación = tabla o archivo
- Registro = registro, fila , renglón o tupla
- Atributo = columna o campo
- Clave = llave o código de identificación
- Clave Candidata = superclave mínima
- Clave Primaria = clave candidata elegida
- Clave Ajena (o foránea) = clave externa o clave foránea
- Clave Alternativa = clave secundaria
- Dependencia Multivaluada = dependencia multivalor
- RDBMS = Del inglés Relational Data Base Manager System que significa, Sistema Gestor de Bases de Datos Relacionales.
- 1FN = Significa, Primera Forma Normal o 1NF del inglés First Normal Form.
Los términos Relación, Tupla y Atributo derivan del álgebra y cálculo relacional, que constituyen la fuente teórica del modelo de base de datos relacional.
Todo atributo en una tabla tiene un dominio, el cual representa el conjunto de valores que el mismo puede tomar. Una instancia de una tabla puede verse entonces como un subconjunto del producto cartesiano entre los dominios de los atributos. Sin embargo, suele haber algunas diferencias con la analogía matemática, ya que algunos RDBMS permiten filas duplicadas, entre otras cosas. Finalmente, una tupla puede razonarse matemáticamente como un elemento del producto cartesiano entre los dominios.
Dependencia
Dependencia funcional

Una dependencia funcional es una conexión entre uno o más atributos. Por ejemplo si se conoce el valor deDNI tiene una conexión con Apellido o Nombre .
Las dependencias funcionales del sistema se escriben utilizando una flecha, de la siguiente manera:
FechaDeNacimiento 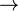 Edad
Edad
Edad
De la normalización (lógica) a la implementación (física o real) puede ser sugerible tener éstas dependencias funcionales para lograr la eficiencia en las tablas.
Propiedades de la Dependencia funcional
Existen 3 axiomas de Armstrong:
Dependencia funcional Reflexiva
Si "y" está incluido en "x" entonces x y
y
A partir de cualquier atributo o conjunto de atributos siempre puede deducirse él mismo. Si la dirección o el nombre de una persona están incluidos en el DNI, entonces con el DNI podemos determinar la dirección o su nombre.
Dependencia funcional Aumentativa
 entonces
entonces 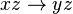
DNI nombre
nombre
DNI,dirección nombre,dirección
nombre,dirección
Si con el DNI se determina el nombre de una persona, entonces con el DNI más la dirección también se determina el nombre y su dirección.
Dependencia funcional transitiva

Sean X, Y, Z tres atributos (o grupos de atributos) de la misma entidad. Si Y depende funcionalmente de X y Z de Y, pero X no depende funcionalmente de Y, se dice entonces que Z depende transitivamente de X. Simbólicamente sería:
X Y Z entonces X Z
Y Z entonces X Z
FechaDeNacimiento Edad
Edad
Edad Conducir
Conducir
FechaDeNacimiento Edad Conducir
Edad Conducir
Entonces tenemos que FechaDeNacimiento determina a Edad y la Edad determina a Conducir, indirectamente podemos saber a través de FechaDeNacimiento a Conducir (En muchos países, una persona necesita ser mayor de cierta edad para poder conducir un automóvil, por eso se utiliza este ejemplo).
"C sera un dato simple (dato no primario), B,sera un otro dato simple (dato no primario), A, es la llave primaria (PK). Decimos que C dependera de B y B dependera funcionalmente de A."
Propiedades deducidas
Unión
y  entonces
entonces 
Pseudo-transitiva
y 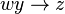 entonces
entonces 
Descomposición
y 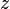 está incluido en
está incluido en  entonces
entonces
Claves
Una clave primaria es aquella columna (o conjunto de columnas) que identifica únicamente a una fila. La clave primaria es un identificador que va a ser siempre único para cada fila. Se acostumbra a poner la clave primaria como la primera columna de la tabla pero es más una conveniencia que una obligación. Muchas veces la clave primaria es numérica auto-incrementada, es decir, generada mediante una secuencia numérica incrementada automáticamente cada vez que se inserta una fila.
En una tabla puede que tengamos más de una columna que puede ser clave primaria por sí misma. En ese caso se puede escoger una para ser la clave primaria y las demás claves seránclaves candidatas.
Una clave ajena (foreign key o clave foránea) es aquella columna que existiendo como dependiente en una tabla, es a su vez clave primaria en otra tabla.
Una clave alternativa es aquella clave candidata que no ha sido seleccionada como clave primaria, pero que también puede identificar de forma única a una fila dentro de una tabla. Ejemplo: Si en una tabla clientes definimos el número de documento (id_cliente) como clave primaria, el número de seguro social de ese cliente podría ser una clave alternativa. En este caso no se usó como clave primaria porque es posible que no se conozca ese dato en todos los clientes.
Una clave compuesta es una clave que está compuesta por más de una columna.
La visualización de todas las posibles claves candidatas en una tabla ayudan a su optimización. Por ejemplo, en una tabla PERSONA podemos identificar como claves su DNI, o el conjunto de su nombre, apellidos, fecha de nacimiento y dirección. Podemos usar cualquiera de las dos opciones o incluso todas a la vez como clave primaria, pero es mejor en la mayoría de sistemas la elección del menor número de columnas como clave primaria.
Formas Normales
Las formas normales son aplicadas a las tablas de una base de datos. Decir que una base de datos está en la forma normal N es decir que todas sus tablas están en la forma normal N.

En general, las primeras tres formas normales son suficientes para cubrir las necesidades de la mayoría de las bases de datos. El creador de estas 3 primeras formas normales (o reglas) fue Edgar Alanis.
Primera Forma Normal (1FN)
Una tabla está en Primera Forma Normal si:
- Todos los atributos son atómicos. Un atributo es atómico si los elementos del dominio son indivisibles, mínimos.
- La tabla contiene una llave primaria única.
- La llave primaria no contiene atributos nulos.
- No debe existir variación en el número de columnas.
- Los Campos no llave deben identificarse por la llave (Dependencia Funcional)
- Debe Existir una independencia del orden tanto de las filas como de las columnas, es decir, si los datos cambian de orden no deben cambiar sus significados
- Una tabla no puede tener múltiples valores en cada columna.
- Los datos son atómicos (a cada valor de X le pertenece un valor de Y y viceversa).
Esta forma normal elimina los valores repetidos dentro de una BD
Segunda Forma Normal (2FN)
Dependencia Funcional. Una relación está en 2FN si está en 1FN y si los atributos que no forman parte de ninguna clave dependen de forma completa de la clave principal. Es decir que no existen dependencias parciales. (Todos los atributos que no son clave principal deben depender únicamente de la clave principal).
En otras palabras podríamos decir que la segunda forma normal está basada en el concepto de dependencia completamente funcional. Una dependencia funcional es completamente funcional si al eliminar los atributos A de X significa que la dependencia no es mantenida, esto es que  . Una dependencia funcional es una dependencia parcial si hay algunos atributos
. Una dependencia funcional es una dependencia parcial si hay algunos atributos  que pueden ser eliminados de X y la dependencia todavía se mantiene, esto es
que pueden ser eliminados de X y la dependencia todavía se mantiene, esto es  .
.
es completamente funcional si al eliminar los atributos A de X significa que la dependencia no es mantenida, esto es que . Una dependencia funcional es una dependencia parcial si hay algunos atributos que pueden ser eliminados de X y la dependencia todavía se mantiene, esto es .
Por ejemplo {DNI, ID_PROYECTO} HORAS_TRABAJO (con el DNI de un empleado y el ID de un proyecto sabemos cuántas horas de trabajo por semana trabaja un empleado en dicho proyecto) es completamente funcional dado que ni DNI HORAS_TRABAJO ni ID_PROYECTO HORAS_TRABAJO mantienen la dependencia. Sin embargo {DNI, ID_PROYECTO} NOMBRE_EMPLEADO es parcialmente dependiente dado que DNI NOMBRE_EMPLEADO mantiene la dependencia.
HORAS_TRABAJO (con el DNI de un empleado y el ID de un proyecto sabemos cuántas horas de trabajo por semana trabaja un empleado en dicho proyecto) es completamente funcional dado que ni DNI HORAS_TRABAJO ni ID_PROYECTO HORAS_TRABAJO mantienen la dependencia. Sin embargo {DNI, ID_PROYECTO} NOMBRE_EMPLEADO es parcialmente dependiente dado que DNI NOMBRE_EMPLEADO mantiene la dependencia.Tercera Forma Normal (3FN)
La tabla se encuentra en 3FN si es 2FN y si no existe ninguna dependencia funcional transitiva entre los atributos que no son clave.
Un ejemplo de este concepto sería que, una dependencia funcional X->Y en un esquema de relación R es una dependencia transitiva si hay un conjunto de atributos Z que no es un subconjunto de alguna clave de R, donde se mantiene X->Z y Z->Y.
Por ejemplo, la dependencia SSN->DMGRSSN es una dependencia transitiva en EMP_DEPT de la siguiente figura. Decimos que la dependencia de DMGRSSN el atributo clave SSN es transitiva vía DNUMBER porque las dependencias SSN→DNUMBER y DNUMBER→DMGRSSN son mantenidas, y DNUMBER no es un subconjunto de la clave de EMP_DEPT. Intuitivamente, podemos ver que la dependencia de DMGRSSN sobre DNUMBER es indeseable en EMP_DEPT dado que DNUMBER no es una clave de EMP_DEPT.
Formalmente, un esquema de relacion 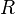 está en 3 Forma Normal Elmasri-Navathe, si para toda dependencia funcional
está en 3 Forma Normal Elmasri-Navathe, si para toda dependencia funcional  , se cumple al menos una de las siguientes condiciones:
, se cumple al menos una de las siguientes condiciones:
está en 3 Forma Normal Elmasri-Navathe, si para toda dependencia funcional , se cumple al menos una de las siguientes condiciones: es superllave o clave.
es superllave o clave. es atributo primo de ; esto es, si es miembro de alguna clave en .
es atributo primo de ; esto es, si es miembro de alguna clave en .
Además el esquema debe cumplir necesariamente, con las condiciones de segunda forma normal.
Forma normal de Boyce-Codd (FNBC)
La tabla se encuentra en FNBC si cada determinante, atributo que determina completamente a otro, es clave candidata. Deberá registrarse de forma anillada ante la presencia de un intervalo seguido de una formalización perpetua, es decir las variantes creadas, en una tabla no se llegaran a mostrar, si las ya planificadas, dejan de existir.
Formalmente, un esquema de relación está en FNBC, si y sólo si, para toda dependencia funcional válida en , se cumple que
está en FNBC, si y sólo si, para toda dependencia funcional válida en , se cumple que- es superllave o clave.
De esta forma, todo esquema que cumple FNBC, está además en 3FN; sin embargo, no todo esquema que cumple con 3FN, está en FNBC.
que cumple FNBC, está además en 3FN; sin embargo, no todo esquema que cumple con 3FN, está en FNBC.Cuarta Forma Normal (4FN)
Una tabla se encuentra en 4FN si, y sólo si, para cada una de sus dependencias múltiples no funcionales X->->Y, siendo X una super-clave que, X es o una clave candidata o un conjunto de claves primarias.
Quinta Forma Normal (5FN)
Una tabla se encuentra en 5FN si:
- La tabla está en 4FN
- No existen relaciones de dependencias no triviales que no siguen los criterios de las claves. Una tabla que se encuentra en la 4FN se dice que está en la 5FN si, y sólo si, cada relación de dependencia se encuentra definida por las claves candidatas.
Reglas de Codd
Codd se percató de que existían bases de datos en el mercado las cuales decían ser relacionales, pero lo único que hacían era guardar la información en las tablas, sin estar estas tablas literalmente normalizadas; entonces éste publicó 12 reglas que un verdadero sistema relacional debería tener, en la práctica algunas de ellas son difíciles de realizar. Un sistema podrá considerarse "más relacional" cuanto más siga estas reglas.
Regla No. 1 - La Regla de la información
Toda la información en un RDBMS está explícitamente representada de una sola manera por valores en una tabla.
Cualquier cosa que no exista en una tabla no existe del todo. Toda la información, incluyendo nombres de tablas, nombres de vistas, nombres de columnas, y los datos de las columnas deben estar almacenados en tablas dentro de las bases de datos. Las tablas que contienen tal información constituyen el Diccionario de Datos. Esto significa que todo tiene que estar almacenado en las tablas.
Toda la información en una base de datos relacional se representa explícitamente en el nivel lógico exactamente de una manera: con valores en tablas. Por tanto los metadatos (diccionario, catálogo) se representan exactamente igual que los datos de usuario. Y puede usarse el mismo lenguaje (ej. SQL) para acceder a los datos y a los metadatos (regla 4)
Regla No. 2 - La regla del acceso garantizado
Cada ítem de datos debe ser lógicamente accesible al ejecutar una búsqueda que combine el nombre de la tabla, su clave primaria, y el nombre de la columna.
Esto significa que dado un nombre de tabla, dado el valor de la clave primaria, y dado el nombre de la columna requerida, deberá encontrarse uno y solamente un valor. Por esta razón la definición de claves primarias para todas las tablas es prácticamente obligatoria.
Regla No. 3 - Tratamiento sistemático de los valores nulos
La información inaplicable o faltante puede ser representada a través de valores nulos
Un RDBMS (Sistema Gestor de Bases de Datos Relacionales) debe ser capaz de soportar el uso de valores nulos en el lugar de columnas cuyos valores sean desconocidos.
Regla No. 4 - La regla de la descripción de la base de datos
La descripción de la base de datos es almacenada de la misma manera que los datos ordinarios, esto es, en tablas y columnas, y debe ser accesible a los usuarios autorizados.
La información de tablas, vistas, permisos de acceso de usuarios autorizados, etc, debe ser almacenada exactamente de la misma manera: En tablas. Estas tablas deben ser accesibles igual que todas las tablas, a través de sentencias de SQL (o similar).
Regla No. 5 - La regla del sub-lenguaje Integral
Debe haber al menos un lenguaje que sea integral para soportar la definición de datos, manipulación de datos, definición de vistas, restricciones de integridad, y control de autorizaciones y transacciones.
Esto significa que debe haber por lo menos un lenguaje con una sintaxis bien definida que pueda ser usado para administrar completamente la base de datos.
Regla No. 6 - La regla de la actualización de vistas
Todas las vistas que son teóricamente actualizables, deben ser actualizables por el sistema mismo.
La mayoría de las RDBMS permiten actualizar vistas simples, pero deshabilitan los intentos de actualizar vistas complejas.
Regla No. 7 - La regla de insertar y actualizar
La capacidad de manejar una base de datos con operandos simples aplica no sólo para la recuperación o consulta de datos, sino también para la inserción, actualización y borrado de datos'.
Esto significa que las cláusulas para leer, escribir, eliminar y agregar registros (SELECT, UPDATE, DELETE e INSERT en SQL) deben estar disponibles y operables, independientemente del tipo de relaciones y restricciones que haya entre las tablas o no.
Regla No. 8 - La regla de independencia física
El acceso de usuarios a la base de datos a través de terminales o programas de aplicación, debe permanecer consistente lógicamente cuando quiera que haya cambios en los datos almacenados, o sean cambiados los métodos de acceso a los datos.
El comportamiento de los programas de aplicación y de la actividad de usuarios vía terminales debería ser predecible basados en la definición lógica de la base de datos, y éste comportamiento debería permanecer inalterado, independientemente de los cambios en la definición física de ésta.
Regla No. 9 - La regla de independencia lógica
Los programas de aplicación y las actividades de acceso por terminal deben permanecer lógicamente inalteradas cuando quiera que se hagan cambios (según los permisos asignados) en las tablas de la base de datos.
La independencia lógica de los datos especifica que los programas de aplicación y las actividades de terminal deben ser independientes de la estructura lógica, por lo tanto los cambios en la estructura lógica no deben alterar o modificar estos programas de aplicación.
Regla No. 10 - La regla de la independencia de la integridad
Todas las restricciones de integridad deben ser definibles en los datos, y almacenables en el catalogo, no en el programa de aplicación.
Las reglas de integridad
- Ningún componente de una clave primaria puede tener valores en blanco o nulos (ésta es la norma básica de integridad).
- Para cada valor de clave foránea deberá existir un valor de clave primaria concordante. La combinación de estas reglas aseguran que haya integridad referencial.
Regla No. 11 - La regla de la distribución
El sistema debe poseer un lenguaje de datos que pueda soportar que la base de datos esté distribuida físicamente en distintos lugares sin que esto afecte o altere a los programas de aplicación.
El soporte para bases de datos distribuidas significa que una colección arbitraria de relaciones, bases de datos corriendo en una mezcla de distintas máquinas y distintos sistemas operativos y que esté conectada por una variedad de redes, pueda funcionar como si estuviera disponible como en una única base de datos en una sola máquina.
Regla No. 12 - Regla de la no-subversión
Si el sistema tiene lenguajes de bajo nivel, estos lenguajes de ninguna manera pueden ser usados para violar la integridad de las reglas y restricciones expresadas en un lenguaje de alto nivel (como SQL).
Algunos productos solamente construyen una interfaz relacional para sus bases de datos No relacionales, lo que hace posible la subversión (violación) de las restricciones de integridad. Esto no debe ser permitido.
Almacen de Datos
Un almacén de datos (del inglés data warehouse) es una colección de datos orientada a un determinado ámbito (empresa, organización, etc.), integrado, no volátil y variable en el tiempo, que ayuda a la toma de decisiones en la entidad en la que se utiliza. Se trata, sobre todo, de un expediente completo de una organización, más allá de la información transaccional y operacional, almacenado en una base de datos diseñada para favorecer el análisis y la divulgación eficiente de datos (especialmente OLAP, procesamiento analítico en línea). El almacenamiento de los datos no debe usarse con datos de uso actual. Los almacenes de datos contienen a menudo grandes cantidades de información que se subdividen a veces en unidades lógicas más pequeñas dependiendo del subsistema de la entidad del que procedan o para el que sean necesario.
Definición de Bill Inmon
Bill Inmon1 fue uno de los primeros autores en escribir sobre el tema de los almacenes de datos, define un data warehouse (almacén de datos) en términos de las características del repositorio de datos:
- Orientado a temas.- Los datos en la base de datos están organizados de manera que todos los elementos de datos relativos al mismo evento u objeto del mundo real queden unidos entre sí.
- Variante en el tiempo.- Los cambios producidos en los datos a lo largo del tiempo quedan registrados para que los informes que se puedan generar reflejen esas variaciones.
- No volátil.- La información no se modifica ni se elimina, una vez almacenado un dato, éste se convierte en información de sólo lectura, y se mantiene para futuras consultas.
- Integrado.- La base de datos contiene los datos de todos los sistemas operacionales de la organización, y dichos datos deben ser consistentes.
Inmon defiende una metodología descendente (top-down) a la hora de diseñar un almacén de datos, ya que de esta forma se considerarán mejor todos los datos corporativos. En esta metodología los Data marts se crearán después de haber terminado el data warehouse completo de la organización.
Definición de Ralph Kimball
Ralph Kimball es otro conocido autor en el tema de los data warehouse, define un almacén de datos como: "una copia de las transacciones de datos específicamente estructurada para la consulta y el análisis". También fue Kimball quien determinó que un data warehouse no era más que: "la unión de todos los Data marts de una entidad". Defiende por tanto una metodología ascendente (bottom-up) a la hora de diseñar un almacén de datos.
Una definición más amplia de almacén de datos
Las definiciones anteriores se centran en los datos en sí mismos. Sin embargo, los medios para obtener y analizar esos datos, para extraerlos, transformarlos y cargarlos, así como las diferentes formas para realizar la gestión de datos son componentes esenciales de un almacén de datos. Muchas referencias a un almacén de datos utilizan esta definición más amplia. Por lo tanto, en esta definición se incluyen herramientas para la inteligencia empresarial, herramientas para extraer, transformar y cargar datos en el almacén de datos, y herramientas para gestionar y recuperar los metadatos.
En un almacén de datos lo que se quiere es contener datos que son necesarios o útiles para una organización, es decir, que se utiliza como un repositorio de datos para posteriormente transformarlos en información útil para el usuario. Un almacén de datos debe entregar la información correcta a la gente indicada en el momento óptimo y en el formato adecuado. El almacén de datos da respuesta a las necesidades de usuarios expertos, utilizando Sistemas de Soporte a Decisiones (DSS), Sistemas de información ejecutiva (EIS) o herramientas para hacer consultas o informes. Los usuarios finales pueden hacer fácilmente consultas sobre sus almacenes de datos sin tocar o afectar la operación del sistema.
En el funcionamiento de un almacén de los datos son muy importantes las siguientes ideas:
- Integración de los datos provenientes de bases de datos distribuidas por las diferentes unidades de la organización y que con frecuencia tendrán diferentes estructuras (fuentes heterogéneas). Se debe facilitar una descripción global y un análisis comprensivo de toda la organización en el almacén de datos.
- Separación de los datos usados en operaciones diarias de los datos usados en el almacén de datos para los propósitos de divulgación, de ayuda en la toma de decisiones, para el análisis y para operaciones de control. Ambos tipos de datos no deben coincidir en la misma base de datos, ya que obedecen a objetivos muy distintos y podrían entorpecerse entre sí.
Periódicamente, se importan datos al almacén de datos de los distintos sistemas de planeamiento de recursos de la entidad (ERP) y de otros sistemas de software relacionados con el negocio para la transformación posterior. Es práctica común normalizar los datos antes de combinarlos en el almacén de datos mediante herramientas de extracción, transformación y carga (ETL). Estas herramientas leen los datos primarios (a menudo bases de datos OLTP de un negocio), realizan el proceso de transformación al almacén de datos (filtración, adaptación, cambios de formato, etc.) y escriben en el almacén.
Data Marts
Los Data marts son subconjuntos de datos de un data warehouse para áreas especificas.
Entre las características de un data mart destacan:
- Usuarios limitados.
- Área especifica.
- Tiene un propósito especifico.
- Tiene una función de apoyo.
Cubos de Informacion
Los cubos de información o cubos OLAP funcionan como los cubos de rompecabezas en los juegos, en el juego se trata de armar los colores y en el data warehouse se trata de organizar los datos por tablas o relaciones; los primeros (el juego) tienen 3 dimensiones, los cubos OLAP tienen un número indefinido de dimensiones, razón por la cual también reciben el nombre de hipercubos. Un cubo OLAP contendrá datos de una determinada variable que se desea analizar, proporcionando una vista lógica de los datos provistos por el sistema de información hacia el data warehouse, esta vista estará dispuesta según unas dimensiones y podrá contener información calculada. El análisis de los datos está basado en las dimensiones del hipercubo, por lo tanto, se trata de un análisis multidimensional.
A la información de un cubo puede acceder el ejecutivo mediante "tablas dinámicas" en una hoja de cálculo o a través de programas personalizados. Las tablas dinámicas le permiten manipular las vistas (cruces, filtrados, organización, totales) de la información con mucha facilidad. Las diferentes operaciones que se pueden realizar con cubos de información se producen con mucha rapidez. Llevando estos conceptos a un data warehouse, éste es una colección de datos que está formada por «dimensiones» y «variables», entendiendo como dimensiones a aquellos elementos que participan en el análisis y variables a los valores que se desean analizar.
Dimensiones
Las dimensiones de un cubo son atributos relativos a las variables, son las perspectivas de análisis de las variables (forman parte de la tabla de dimensiones). Son catálogos de información complementaria necesaria para la presentación de los datos a los usuarios, como por ejemplo: descripciones, nombres, zonas, rangos de tiempo, etc. Es decir, la información general complementaria a cada uno de los registros de la tabla de hechos.
Variables
También llamadas “indicadores de gestión”, son los datos que están siendo analizados. Forman parte de la tabla de hechos. Más formalmente, las variables representan algún aspecto cuantificable o medible de los objetos o eventos a analizar. Normalmente, las variables son representadas por valores detallados y numéricos para cada instancia del objeto o evento medido. En forma contraria, las dimensiones son atributos relativos a las variables, y son utilizadas para indexar, ordenar, agrupar o abreviar los valores de las mismas. Las dimensiones poseen una granularidad menor, tomando como valores un conjunto de elementos menor que el de las variables; ejemplos de dimensiones podrían ser: “productos”, “localidades” (o zonas), “el tiempo” (medido en días, horas, semanas, etc.), ...
Ejemplos
Ejemplos de variables podrían ser:
- Beneficios
- Gastos
- Ventas
- etc.
Ejemplos de dimensiones podrían ser:
- producto (diferentes tipos o denominaciones de productos)
- localidades (o provincia, o regiones, o zonas geográficas)
- tiempo (medido de diferentes maneras, por horas, por días, por meses, por años, ...)
- tipo de cliente (casado/soltero, joven/adulto/anciano, ...)
- etc.
Según lo anterior, podríamos construir un cubo de información sobre el índice de ventas (variable a estudiar) en función del producto vendido, la provincia, el mes del año y si el cliente estácasado o soltero (dimensiones). Tendríamos un cubo de 4 dimensiones.
Elementos que integran un Almacen de Datos
Metadatos
Uno de los componentes más importantes de la arquitectura de un almacén de datos son los metadatos. Se define comúnmente como "datos acerca de los datos", en el sentido de que se trata de datos que describen cuál es la estructura de los datos que se van a almacenar y cómo se relacionan.
El metadato documenta, entre otras cosas, qué tablas existen en una base de datos, qué columnas posee cada una de las tablas y qué tipo de datos se pueden almacenar. Los datos son de interés para el usuario final, el metadato es de interés para los programas que tienen que manejar estos datos. Sin embargo, el rol que cumple el metadato en un entorno de almacén de datos es muy diferente al rol que cumple en los ambientes operacionales. En el ámbito de los data warehouse el metadato juega un papel fundamental, su función consiste en recoger todas las definiciones de la organización y el concepto de los datos en el almacén de datos, debe contener toda la información concerniente a:
- Tablas
- Columnas de tablas
- Relaciones entre tablas
- Jerarquías y Dimensiones de datos
- Entidades y Relaciones
Funciones ETL (extracción, transformación y carga)
Los procesos de extracción, transformación y carga (ETL) son importantes ya que son la forma en que los datos se guardan en un almacén de datos (o en cualquier base de datos). Implican las siguientes operaciones:
- Extracción. Acción de obtener la información deseada a partir de los datos almacenados en fuentes externas.
- Transformación. Cualquier operación realizada sobre los datos para que puedan ser cargados en el data warehouse o se puedan migrar de éste a otra base de datos.
- Carga. Consiste en almacenar los datos en la base de datos final, por ejemplo el almacén de datos objetivo normal.
Middleware
Middleware es un término genérico que se utiliza para referirse a todo tipo de software de conectividad que ofrece servicios u operaciones que hacen posible el funcionamiento de aplicaciones distribuidas sobre plataformas heterogéneas. Estos servicios funcionan como una capa de abstracción de software distribuida, que se sitúa entre las capas de aplicaciones y las capas inferiores (sistema operativo y red). El middleware puede verse como una capa API, que sirve como base a los programadores para que puedan desarrollar aplicaciones que trabajen en diferentes entornos sin preocuparse de los protocolos de red y comunicaciones en que se ejecutarán. De esta manera se ofrece una mejor relación costo/rendimiento que pasa por el desarrollo de aplicaciones más complejas, en menos tiempo.
La función del middleware en el contexto de los data warehouse es la de asegurar la conectividad entre todos los componentes de la arquitectura de un almacén de datos.
Diseño de un almacén de datos
Para construir un Data Warehouse se necesitan herramientas para ayudar a la migración y a la transformación de los datos hacia el almacén. Una vez construido, se requieren medios para manejar grandes volúmenes de información. Se diseña su arquitectura dependiendo de la estructura interna de los datos del almacén y especialmente del tipo de consultas a realizar. Con este criterio los datos deben ser repartidos entre numerosos data marts. Para abordar un proyecto de data warehouse es necesario hacer un estudio de algunos temas generales de la organización o empresa, los cuales se describen a continuación:
- Situación actual de partida.- Cualquier solución propuesta de data warehouse debe estar muy orientada por las necesidades del negocio y debe ser compatible con la arquitectura técnica existente y planeada de la compañía.
- Tipo y características del negocio.- Es indispensable tener el conocimiento exacto sobre el tipo de negocios de la organización y el soporte que representa la información dentro de todo su proceso de toma de decisiones.
- Entorno técnico.- Se debe incluir tanto el aspecto del hardware (mainframes, servidores, redes,...) así como aplicaciones y herramientas. Se dará énfasis a los Sistemas de soporte a decisiones (DSS), si existen en la actualidad, cómo operan, etc.
- Expectativas de los usuarios.- Un proyecto de data warehouse no es únicamente un proyecto tecnológico, es una forma de vida de las organizaciones y como tal, tiene que contar con el apoyo de todos los usuarios y su convencimiento sobre su bondad.
- Etapas de desarrollo.- Con el conocimiento previo, ya se entra en el desarrollo de un modelo conceptual para la construcción del data warehouse.
- Prototipo.- Un prototipo es un esfuerzo designado a simular tanto como sea posible el producto final que será entregado a los usuarios.
- Piloto.- El piloto de un data warehouse es el primero, o cada uno de los primeros resultados generados de forma iterativa que se harán para llegar a la construcción del producto final deseado.
- Prueba del concepto tecnológico.- Es un paso opcional que se puede necesitar para determinar si la arquitectura especificada del data warehouse funcionará finalmente como se espera.
Almacén de datos espacial
Almacén de datos espacial es una colección de datos orientados al tema, integrados, no volátiles, variantes en el tiempo y que añaden la geografía de los datos, para la toma de decisiones. Sin embargo la componente geográfica no es un dato agregado, sino que es una dimensión o variable en la tecnología de la información, de tal manera que permita modelar todo el negocio como un ente holístico, y que a través de herramientas de procesamiento analítico en línea (OLAP), no solamente se posea un alto desempeño en consultas multidimensionales sino que adicionalmente se puedan visualizar espacialmente los resultados.
El almacén de datos espacial forma el corazón de un extensivo Sistema de Información Geográfica para la toma de decisiones, éste al igual que los SIG, permiten que un gran número de usuarios accedan a información integrada, a diferencia de un simple almacén de datos que está orientado al tema, el Data warehouse espacial adicionalmente es Geo-Relacional, es decir que en estructuras relacionales combina e integra los datos espaciales con los datos descriptivos. Actualmente es geo-objetos, esto es que los elementos geográficos se manifiestan como objetos con todas sus propiedades y comportamientos, y que adicionalmente están almacenados en una única base de datos Objeto-Relacional. Los Data Warehouse Espaciales son aplicaciones basadas en un alto desempeño de las bases de datos, que utilizan arquitecturas Cliente-Servidor para integrar diversos datos en tiempo real. Mientras los almacenes de datos trabajan con muchos tipos y dimensiones de datos, muchos de los cuales no referencian ubicación espacial, a pesar de poseerla intrínsecamente, y sabiendo que un 80% de los datos poseen representación y ubicación en el espacio, en los Data warehouse espaciales, la variable geográfica desempeña un papel importante en la base de información para la construcción del análisis, y de igual manera que para unData warehouse, la variable tiempo es imprescindible en los análisis, para los Data warehouse espaciales la variable geográfica debe ser almacenada directamente en ella.
Ventajas e inconvenientes de los almacenes de datos
Ventajas
Hay muchas ventajas por las que es recomendable usar un almacén de datos. Algunas de ellas son:
- Los almacenes de datos hacen más fácil el acceso a una gran variedad de datos a los usuarios finales
- Facilitan el funcionamiento de las aplicaciones de los sistemas de apoyo a la decisión tales como informes de tendencia', por ejemplo: obtener los ítems con la mayoría de las ventas en un área en particular dentro de los últimos dos años; informes de excepción, informes que muestran los resultados reales frente a los objetivos planteados a priori.
- Los almacenes de datos pueden trabajar en conjunto y, por lo tanto, aumentar el valor operacional de las aplicaciones empresariales, en especial la gestión de relaciones con clientes.
Inconvenientes
Utilizar almacenes de datos también plantea algunos inconvenientes, algunos de ellos son:
- A lo largo de su vida los almacenes de datos pueden suponer altos costos. El almacén de datos no suele ser estático. Los costos de mantenimiento son elevados.
- Los almacenes de datos se pueden quedar obsoletos relativamente pronto.
- A veces, ante una petición de información estos devuelven una información subóptima, que también supone una pérdida para la organización.
- A menudo existe una delgada línea entre los almacenes de datos y los sistemas operacionales. Hay que determinar qué funcionalidades de estos se pueden aprovechar y cuáles se deben implementar en el data warehouse, resultaría costoso implementar operaciones no necesarias o dejar de implementar alguna que sí vaya a necesitarse.
Tabla de Hechos
En las bases de datos, y más concretamente en un data warehouse, una tabla de hechos (o tabla fact) es la tabla central de un esquema dimensional (en estrella o en copo de nieve) y contiene los valores de las medidas de negocio. Cada medida se toma mediante la intersección de las dimensiones que la definen, dichas dimensiones estarán reflejadas en sus correspondientes tablas de dimensiones que rodearán la tabla de hechos y estarán relacionadas con ella.
En la figura de la derecha, la tabla central (Ventas) es la tabla de hechos de un diseño de modelo de datos en estrella, las cinco tablas que la rodean (Producto, Tiempo, Almacén, Promoción y Cliente) son las cinco dimensiones de que consta esta tabla de hechos, en dicha tabla se almacenan, en este caso, las unidades vendidas y el precio obtenido por dichas ventas, estos son los hechos o medidas de negocio almacenados y que, gracias al diseño multidimensional en estrella, podrán ser analizados de forma exhaustiva, típicamente mediante técnicas OLAP (procesamiento analítico on-line).
Cardinalidad de la Tabla de Hechos
Las tablas de hechos pueden contener un gran número de filas, a veces cientos de millones de registros cuando contienen uno o más años de la historia de una gran organización, esta cardinalidad estará acotada superiormente por la cardinalidad de las tablas dimensionales, Por ejemplo, si se tiene una tabla de hechos "TH" de tres dimensiones D1, D2 y D3, el número máximo de elementos que tendrá la tabla de hechos TH será:
Donde 'Card(x)' es la cardinalidad de la tabla 'x'
Naturalmente, estas cardinalidades no son fijas, ya que, por ejemplo, si una de las dimensiones se refiere a los clientes de la empresa, cada vez que se dé de alta un nuevo cliente se estará aumentando la cardinalidad de la tabla de hechos. Una de las dimensiones suele ser el tiempo, éste puede medirse de muy distintas formas (por horas, días, semanas, ...), pero lo cierto es que transcurre continuamente, y para que el sistema funcione se deben añadir registros periódicamente a la tabla de esta dimensión (tabla de tiempos) y esto también produce un aumento de la cardinalidad de la tabla de hechos, ésta es la principal causa de que las tablas de hechos lleguen a tener una cantidad de registros del orden de millones de elementos.
Granularidad
Una característica importante que define a una tabla de hechos es el nivel de granularidad de los datos que en ella se almacenan, entendiéndose por 'granularidad' el nivel de detalle de dichos datos, es decir, la granularidad de la tabla de hechos representa el nivel más atómico por el cual se definen los datos. Por ejemplo, no es lo mismo contar el tiempo por horas (grano fino) que por semanas (grano grueso); o en el caso de los productos, se puede considerar cada variante de un mismo artículo como un producto (por ejemplo, en una empresa textil, cada talla y color de pantalón podría ser un producto) o agrupar todos los artículos de una misma familia considerándolos como un único producto (por ejemplo, el producto pantalón genérico).
Como se puede observar, la granularidad afecta a la cardinalidad, tanto de las dimensiones como de la tabla de hechos, a mayor granularidad (grano más fino) mayor será el número de registros final de la tabla de hechos.
Cuando la granularidad es mayor, es frecuente que se desee disponer de subtotales parciales, es decir, si tenemos una tabla de hechos con las ventas por días, podría interesar disponer de los totales semanales o mensuales, estos datos se pueden calcular haciendo sumas parciales, pero es frecuente añadir a la tabla de hechos registros donde se almacenan dichos cálculos para no tener que repetirlos cada vez que se requieran y mejorar así el rendimiento de la aplicación. En este caso se dispondrá en la misma tabla de hechos de datos de grano fino y de grano más grueso aumentando aún más la cardinalidad de la tabla.
Agregación
La agregación es un proceso de cálculo por el cual se resumen los datos de los registros de detalle. Esta operación consiste normalmente en el cálculo de totales dando lugar a medidas de grano grueso. Cuando se resumen los datos, el detalle ya no está directamente disponible para el analista, ya que este se elimina de la tabla de hechos.
Esta operación se realiza típicamente con los datos más antiguos de la empresa con la finalidad de seguir disponiendo de dicha información (aunque sea resumida) para poder eliminar registros obsoletos de la tabla de hechos para liberar espacio.
Tablas de Dimension
En un almacen de datos o un sistema Olap, la construcción de cubos olap requiere de una tabla de hechos y varias tablas de dimensiones, éstas acompañan a la tabla de hechos y determinan los parámetros (dimensiones) de los que dependen los hechos registrados en la tabla de hechos.
En la construcción de cubos OLAP, las tablas de dimensiones son elementos que contienen atributos (o campos) que se utilizan para restringir y agrupar los datos almacenados en una tabla de hechos cuando se realizan consultas sobre dicho datos en un entorno de almacén de datos o data mart.
Estos datos sobre dimensiones son parámetros de los que dependen otros datos que serán objeto de estudio y análisis y que están contenidos en la tabla de hechos. Las tablas de dimensiones ayudan a realizar ese estudio/análisis aportando información sobre los datos de la tabla de hechos, por lo que puede decirse que en un cubo OLAP, la tabla de hechos contiene los datos de interés y las tablas de dimensiones contienen metadatos sobre dichos hechos.
Granularidad de dimensión y jerarquías
Cada dimensión puede referirse a conceptos como 'tiempo', 'productos', 'clientes', 'zona geográfica', etc. Ahora bien, cada dimensión puede estar medida de diferentes maneras según la granularidad deseada, por ejemplo, para la dimensión "zona geográfica" podríamos considerar 'localidades', 'provincias', 'regiones', 'países' o 'continentes'.



La unidad de medida (por localidades, provincias, etc.) determinará esa granularidad, cuanto más pequeña sea esta unidad de medida más fina será esta granularidad (grano fino); si las unidades de medida son mayores, entonces hablaremos de granularidad gruesa (grano grueso).
En muchas ocasiones interesa disponer de los datos a varios niveles de granularidad, es decir, es importante para el negocio poder consultar los datos (siguiendo el ejemplo de las zonas) por localidades, provincias, etc., en estos casos se crea una jerarquía con la dimensión, ya que tenemos varios niveles de asociación de los datos (con otras dimensiones como el tiempo, se podrían crear niveles jerárquicos del tipo 'días', 'semanas', 'meses', ...).
Cuando las tablas de dimensión asociadas a una tabla de hechos no reflejan ninguna jerarquía (por ejemplo: Las zonas siempre son 'provincias' y sólo provincias, el tiempo se mide en 'días' y sólo en días, etc.) el cubo resultante tendrá forma de estrella, es decir, una tabla de hechos central rodeada de tantas tablas como dimensiones, y sólo habrá, además de la tabla de hechos, una tabla por cada dimensión.
Cuando una o varias de las dimensiones del cubo refleja algún tipo de jerarquía existen dos planteamientos con respecto a la forma que deben ser diseñadas las tablas de dimensión. El primero consiste en reflejar todos los niveles jerárquicos de una dimensión dentro de una única tabla, en este caso también tendríamos un esquema en estrella como el que se ha descrito anteriormente.
El otro planteamiento consiste en aplicar a las dimensiones las reglas de normalización de las bases de datos relacionales. Estas normas están ideadas para evitar redundancias en los datos aumentando el número de tablas, de esta forma se consigue almacenar la información en menos espacio. Este diseño da como resultado en esquema en copo de nieve. Este modo de organizar las dimensiones de un cubo OLAP tiene un inconveniente respecto al modelo en estrella que no compensa el ahorro de espacio de almacenamiento. En las aplicaciones OLAP el recurso crítico, no es tanto el espacio para almacenamiento como el tiempo de respuesta del sistema ante consultas del usuario, y está constatado que los modelos en copo de nieve tienen un tiempo de respuesta mayor que los modelos en estrella.


La dimensión "tiempo"
En cualquier Dataware house se pueden encontrar varios cubos con sus tablas de hechos repletas de registros sobre alguna variable de interés para el negocio que debe ser estudiada. Como ya se ha comentado, cada tabla de hechos estará rodeada de varias tablas de dimensiones, según que parámetros sirvan mejor para realizar el análisis de los hechos que se quieren estudiar. Un parámetro que casi con toda probabilidad será común a todos los cubos es el tiempo, ya que lo habitual es almacenar los hechos conforme van ocurriendo a lo largo del tiempo, obteniéndose así una serie temporal de la variable a estudiar.
| ||||||||||
|
Dado que el tiempo es una dimensión presente en prácticamente cualquier cubo de un sistema OLAP merece una atención especial. Al diseñar la dimensión tiempo (tanto para un esquema en estrella como para un esquema en copo de nieve) hay que prestar especial cuidado, ya que puede hacerse de varias maneras y no todas son igualmente eficientes. La forma más común de diseñar esta tabla es poniendo como clave principal (PK) de la tabla la fecha ofecha/hora (tabla de tiempos 1). Este diseño no es de los más recomendables, ya que a la mayoría de los sistemas de gestión de bases de datos les resulta más costoso hacer búsquedas sobre campos de tipo "date" o "datetime", estos costes se reducen si el campo clave es de tipo entero, además, un dato entero siempre ocupa menos espacio que un dato de tipo fecha (el campo clave se repetirá en millones de registros en la tabla de hechos y eso puede ser mucho espacio), por lo que se mejorará el diseño de la tabla de tiempos si se utiliza un campo "TiempoID" de tipo entero como clave principal (tabla de tiempos 2).
A la hora de rellenar la tabla de tiempos, si se ha optado por un campo de tipo entero para la clave, hay dos opciones, la que quizá sea más inmediata consiste en asignar valores numéricos consecutivos (1, 2, 3, 4, ...) para los diferentes valores de fechas. La otra opción consistiría en asignar valores numéricos del tipo "yyyymmdd", es decir que los cuatro primeros dígitos del valor del campo indican el año de la fecha, los dos siguientes el mes y los dos últimos el día. Este segundo modo aporta una cierta ventaja sobre el anterior, ya que de esta forma se consigue que el dato numérico en sí, aporte por si solo la información de a que fecha se refiere, es decir, si en la tabla de hechos encontramos el valor 20040723, sabremos que se refiere al día 23 de julio de 2004; en cambio, con el primer método, podríamos encontrar valores como 8456456, para saber a que fecha se refiere este valor tendríamos que hacer una consulta sobre la tabla de tiempos.
Además del campo clave TiempoID, la tabla de hechos debe contener otros campos que también es importante estudiar. Estos campos serían:
|
- Un campo "año".- Para contener valores como '2002', 2003, '2004', ...
- Un campo "mes".- Aquí se pueden poner los valores 'Enero', 'Febrero', ... (o de forma abreviada: 'Ene', 'Feb', ...), esto no está mal, pero se puede mejorar si el nombre del mes va acompañado con el año al que pertenece, es decir '2004 Enero', '2004 Febrero', ... de esta forma se optimiza la búsqueda de los valores de un mes en concreto, ya que con el primer método, si se buscan los valores pertenecientes al mes de "Enero de 2003", toda esa información está contenida en un sólo campo, el "mes", no haría falta consultar también el campo año.
- Un campo "mesID".- Este campo tendría que ser de tipo entero y serviría para almacenar valores del tipo 200601 (para '2006 Enero') o 200602 (para '2006 Febrero'), de esta forma es posible realizar ordenaciones y agrupaciones por meses.
De forma análoga a como se ha hecho con el campo mes, se podrían añadir más campos como "Época del año", "Trimestre", "Quincena", "Semana" de tipo texto para poder visualizarlos, y sus análogos de tipo entero "Época del año_ID", "TrimestreID", "QuincenaID", "SemanaID" para poder realizar agrupaciones y ordenaciones. En general se puede añadir un campo por cada nivel de granularidad deseado.
Otro campo especial que se puede añadir es el "Día de la semana" ('lunes', 'martes', ...), este campo se suele añadir para poder hacer estudios sobre el comportamiento de los días de la semana en general (no del primer lunes del mes de enero de un año concreto, este tipo de estudio no suele tener interés), por esta razón, este campo no necesita ir acompañado del mes o del año como los campos anteriores. También se puede añadir su campo dual "ID" de tipo entero para poder ordenar y agrupar si fuera necesario.
Con los añadidos descritos podríamos tener una tabla de tiempos como la de la figura "Tabla de tiempos (3)". Esta sería válida para un diseño en estrella, para un diseño en copo de nieve habría que desglosar la tabla de tiempos en tantas tablas como niveles jerárquicos contenga. Obsérvese que los campos de tipo "ID" son todos de tipo entero, ya que será sobre estos campos sobre los que se realizarán la mayoría de las operaciones y estas se realizarán más eficientemente sobre datos enteros.
Modelo de Bases de Datos
Un modelo de base de datos es la fundación teórica de una base de datos y fundamentalmente determina de que manera los datos van a ser guardados, organizados y manipulados en un sistema de base de datos. De esta forma, define la infraestructura ofrecida por un sistema de base de datos particular. El ejemplo mas popular de un modelo de base de datos, es el modelo relacional
Los esquemas generalmente son almacenados en un diccionario de datos. Aunque un esquema se defina en un lenguaje de base de datos de texto, el término a menudo es usado para referirse a una representación gráfica de la estructura de la base de datos.
Un modelo de base de datos es una teoría o especificación que describe como una base de datos es estructurada y usada. Varios modelos han sido sugeridos.
Modelos comunes:
- Modelo jerárquico
- Modelo de red
- Modelo relacional
- Modelo entidad-relación
- Modelo objeto-relacional
- Modelo de objeto también define el conjunto de las operaciones que pueden ser realizadas sobre los datos. El modelo relacional, por ejemplo, define operaciones como selección, proyección y unión. Aunque estas operaciones pueden no ser explícitas en un lenguaje de consultas particular, proveen las bases sobre las que éstos son construidos.
Varias técnicas son usadas para modelar la estructura de datos. La mayor parte de sistemas de base de datos son construidos en torno a un modelo de datos particular, aunque sea cada vez más común para productos ofrecer el apoyo a más de un modelo. Ya que cualquier varia puesta en práctica lógica modela física puede ser posible, y la mayor parte de productos ofrecerán al usuario algún nivel de control en la sintonía de la puesta en práctica física, desde las opciones que son hechas tienen un efecto significativo sobre el funcionamiento. Un ejemplo de esto es el modelo emparentado: todas las puestas en práctica serias del modelo emparentado permiten la creación de índices que proporcionan rápido acceso a filas en una tabla si conocen los valores de ciertas columnas.
Modelo de tabla
El modelo de tabla consiste en una serie única, bidimensional de elementos de datos, donde todos los miembros de una columna dada son asumidos para ser valores similares, y todos los miembros de una fila son asumidos para ser relacionados el uno con el otro. Por ejemplo, columnas para el nombre y la contraseña que podría ser usada como una parte de una base de datos de seguridad de sistema. Cada fila tendría la contraseña específica asociada con un usuario individual. Las columnas de la tabla a menudo tienen un tipo asociado con ellos, definiéndolos como datos de carácter, fecha o la información de tiempo, números enteros, o números de punto flotante.
Modelo jerárquico
En un modelo jerárquico, los datos son organizados en una estructura parecida a un árbol, implicando un eslabón solo ascendente en cada registro para describir anidar, y un campo de clase para guardar los registros en un orden particular en cada lista de mismo-nivel. Las estructuras jerárquicas fueron usadas extensamente en los primeros sistemas de gestión de datos de unidad central, como el Sistema de Dirección de Información (IMS) por la IBM, y ahora describen la estructura de documentos XML. Esta estructura permite un 1:N en una relación entre dos tipos de datos. Esta estructura es muy eficiente para describir muchas relaciones en el verdadero real; recetas, índice, ordenamiento de párrafos/versos, alguno anidó y clasificó la información. Sin embargo, la estructura jerárquica es ineficaz para ciertas operaciones de base de datos cuando un camino lleno (a diferencia del eslabón ascendente y el campo de clase) también no es incluido para cada registro.
Una limitación del modelo jerárquico es su inhabilidad de representar manera eficiente la redundancia en datos. Los modelos de base de datos " el valor de atributo de entidad " como Caboodle por Swink están basados en esta estructura.
En la relación Padre-hijo: El hijo sólo puede tener un padre pero un padre puede tener múltiples hijos. Los padres e hijos son atados juntos por eslabones "indicadores" llamados. Un padre tendrá una lista de indicadores de cada uno de sus hijos.
Modelo de red
El modelo de red (definido por la especificación CODASYL) organiza datos que usan dos fundamental construcciones, registros llamados y conjuntos. Los registros contienen campos (que puede ser organizado jerárquicamente, como en el lenguaje COBOL de lenguaje de programación). Los conjuntos (para no ser confundido con conjuntos matemáticos) definen de uno a varios relaciones entre registros: un propietario, muchos miembros. Un registro puede ser un propietario en cualquier número de conjuntos, y un miembro en cualquier número de conjuntos.
El modelo de red es una variación sobre el modelo jerárquico, al grado que es construido sobre el concepto de múltiples ramas(estructuras de nivel inferior) emanando de uno o varios nodos (estructuras de nivel alto), mientras el modelo se diferencia del modelo jerárquico en esto las ramas pueden estar unidas a múltiples nodos. El modelo de red es capaz de representar la redundancia en datos de una manera más eficiente que en el modelo jerárquico.
Las operaciones del modelo de red son de navegación en el estilo: un programa mantiene una posición corriente, y navega de un registro al otro por siguiente las relaciones en las cuales el registro participa. Los registros también pueden ser localizados por suministrando valores claves.
Aunque esto no sea un rasgo esencial del modelo, las bases de datos de red generalmente ponen en práctica las relaciones de juego mediante indicadores que directamente dirigen la ubicación de un registro sobre el disco. Esto da el funcionamiento de recuperación excelente, a cargo de operaciones como la carga de base de datos y la reorganización.
La mayor parte de bases de datos de objeto usan el concepto de navegación para proporcionar la navegación rápida a través de las redes de objetos, generalmente usando identificadores de objeto como indicadores "inteligentes" de objetos relacionados. Objectivity/DB, por ejemplo, los instrumentos llamados 1:1, 1:muchos, muchos:1 y muchos:muchos, llamados relaciones que pueden cruzar bases de datos. Muchas bases de datos de objeto también apoyan SQL, combinando las fuerzas de ambos modelos.
El modelo de red (definido por la especificación CODASYL) organiza datos que usan dos fundamental construcciones, registros llamados y conjuntos. Los registros contienen campos (que puede ser organizado jerárquicamente, como en el lenguaje COBOL de lenguaje de programación). Los conjuntos (para no ser confundido con conjuntos matemáticos) definen de uno a varios relaciones entre registros: un propietario, muchos miembros. Un registro puede ser un propietario en cualquier número de conjuntos, y un miembro en cualquier número de conjuntos. El modelo de red es una variación sobre el modelo jerárquico, al grado que es construido sobre el concepto de múltiples ramas(estructuras de nivel inferior) emanando de uno o varios nodos (estructuras de nivel alto), mientras el modelo se diferencia del modelo jerárquico en esto las ramas pueden estar unidas a múltiples nodos. El modelo de red es capaz de representar la redundancia en datos de una manera más eficiente que en el modelo jerárquico.efinen de uno a varios relaciones entre registros: un propietario, muchos miembros. Un registro puede ser un propietario en cualquier númer Las operaciones del modelo de red son de navegación en el estilo: un programa mantiene una posición corriente, y navega de un registro al otro por siguiente las relaciones en las cuales el registro participa. Los registros también pueden ser localizados por suministrando valores claves. Aunque esto no sea un rasgo esencial del modelo, las bases de datos de red generalmente ponen en práctica las relaciones de juego mediante indicadores que directamente. dirigen la ubicación de un registro sobre el disco. Esto da el funcionamiento de recuperación excelente, a cargo de operaciones como la carga de base de datos y la reorganización.efinen de uno a varios relaciones entre registros: un propietario, muchos miembros. Un registro puede ser un propietario en cualquier númer
Modelo Dimensional
El modelo dimensional es una adaptación especializada del modelo relacional, solía representar datos en depósitos de datos, en un camino que los datos fácilmente pueden ser resumidos usando consultas OLAP. En el modelo dimensional, una base de datos consiste en una sola tabla grande de hechos que son descritos usando dimensiones y medidas.
Una dimensión proporciona el contexto de un hecho (como quien participó, cuando y donde pasó, y su tipo). Las dimensiones se toman en cuenta en la formulación de las consultas para agrupar hechos que están relacionados. Las dimensiones tienden a ser discretas y son a menudo jerárquicas; por ejemplo, la ubicación podría incluir el edificio, el estado, y el país.
Una medida es una cantidad que describe el hecho, tales como los ingresos. Es importante que las medidas puedan ser agregados significativamente - por ejemplo, los ingresos provenientes de diferentes lugares pueden sumarse.
En una consulta (OLAP), las dimensiones son escogidas y los hechos son agrupados y añadidos juntos para crear un reporte.
El modelo dimensional a menudo es puesto en práctica sobre la cima del modelo emparentado que usa un esquema de estrella, consistiendo en una mesa que contiene los hechos y mesas circundantes que contienen las dimensiones. Dimensiones en particular complicadas podrían ser representadas usando múltiples mesas, causando un esquema de copo de nieve.
Un almacen de datos (data warehouse) puede contener múltiples esquemas de estrella que comparten tablas de dimensión, permitiéndoles para ser usadas juntas. La llegada levanta un conjunto de dimensiones estándar y es una parte importante del modelado dimensional.
Modelo de objeto
En años recientes, el paradigma mediante objetos ha sido aplicado a la tecnología de base de datos, creando un nuevo modelo de programa sabido(conocido) como bases de datos de objeto. Estas bases de datos intentan traer el mundo de base de datos y el uso que programa el mundo más cerca juntos, en particular por asegurando que la base de datos usa el mismo sistema de tipo que el programa de uso. Esto apunta para evitar el elevado (a veces mencionaba el desajuste de impedancia) de convertir la información entre su representación en la base de datos (por ejemplo como filas en mesas) y su representación en el programa de uso (típicamente como objetos). Al mismo tiempo, las bases de datos de objeto intentan introducir las ideas claves de programa de objeto, como encapsulation y polimorfismo, en el mundo de bases de datos.
Una variedad de estas formas ha sido aspirada almacenando objetos en una base de datos. Algunos productos se han acercado al problema del uso que programa el final, por haciendo los objetos manipulados según el programa persistente. Esto también típicamente requiere la adición de una especie de lengua de pregunta, ya que lenguajes de programación convencionales no tienen la capacidad de encontrar objetos basados en su contenido de la información. Los otros han atacado el problema a partir del final de base de datos, por definiendo un modelo de datos mediante objetos para la base de datos, y definiendo un lenguaje de programación de base de datos que permite a capacidades de programa llenas así como instalaciones de pregunta tradicionales.
Las bases de datos de objeto han sufrido debido a la carencia de estandarización: aunque las normas fueran definidas por ODMG, nunca fueron puestas en práctica lo bastante bien para asegurar la interoperabilidad entre productos. Sin embargo, las bases de datos de objeto han sido usadas satisfactoriamente en muchos usos:Usualmente aplicaciones especialisadas como bases de datos de ingenieria, base de datos biologica molecualar, más bien que proceso de datos establecido comercial. Sin embargo, las ideas de base de datos de objeto fueron recogidas por los vendedores emparentados y extensiones influidas hechas a estos productos y de verdad a la lengua SQL.
Mineria de Datos
La minería de datos (es la etapa de análisis de "Knowledge Discovery in Databases" o KDD), es un campo de las ciencias de la computación referido al proceso que intenta descubrir patrones en grandes volúmenes de conjuntos de datos. Utiliza los métodos de la inteligencia artificial, aprendizaje automático, estadística y sistemas de bases de datos. El objetivo general del proceso de minería de datos consiste en extraer información de un conjunto de datos y transformarla en una estructura comprensible para su uso posterior. Además de la etapa de análisis en bruto, que involucra aspectos de bases de datos y gestión de datos, procesamiento de datos, el modelo y las consideraciones de inferencia, métricas de Intereses, consideraciones de la Teoría de la complejidad computacional, post-procesamiento de las estructuras descubiertas, la visualización y actualización en línea.
El término es una palabra de moda, y es frecuentemente mal utilizado para referirse a cualquier forma de datos a gran escala o procesamiento de la información (recolección, extracción, almacenamiento, análisis y estadísticas), pero también se ha generalizado a cualquier tipo de sistema de apoyo informático decisión, incluyendo la inteligencia artificial , aprendizaje automático y la inteligencia empresarial. En el uso de la palabra, el término clave es el descubrimiento, comúnmente se define como "la detección de algo nuevo". Incluso el popular libro "La minería de datos: sistema de prácticas herramientas de aprendizaje y técnicas con Java" (que cubre todo el material de aprendizaje automático) originalmente iba a ser llamado simplemente "la máquina de aprendizaje práctico", y el término "minería de datos" se añadió por razones de marketing. A menudo, los términos más generales "(gran escala) el análisis de datos", o "análisis" -. o cuando se refiere a los métodos actuales, la inteligencia artificial y aprendizaje automático, son más apropiados.
La tarea de minería de datos real es el análisis automático o semi-automático de grandes cantidades de datos para extraer patrones interesantes hasta ahora desconocidos, como los grupos de registros de datos (análisis cluster), registros poco usuales (la detección de anomalías) y dependencias (Asociación Minera regla). Esto generalmente implica el uso de técnicas de bases de datos como los índices espaciales. Estos patrones pueden entonces ser visto como una especie de resumen de los datos de entrada, y puede ser utilizado en el análisis adicional o, por ejemplo, en la máquina de aprendizaje y análisis predictivo. Por ejemplo, el paso de minería de datos podrían identificar varios grupos en los datos, que luego pueden ser utilizados para obtener resultados más precisos de predicción por un sistema de soporte de decisiones. Ni la recolección de datos, preparación de datos, ni la interpretación de los resultados y la información son parte de la etapa de minería de datos, pero que pertenecen a todo el proceso KDD como pasos adicionales.
Los términos relacionados con el dragado de datos, la pesca de datos y espionaje de los datos se refieren a la utilización de métodos de minería de datos a las partes de la muestra de un conjunto de datos de población más grandes establecidas que son (o pueden ser) demasiado pequeño para las inferencias estadísticas fiables que se hizo acerca de la validez de cualquier patrones descubiertos. Estos métodos pueden, sin embargo, ser utilizado en la creación de nuevas hipótesis que se prueba contra las poblaciones de datos más grandes.
Un proceso típico de minería de datos consta de los siguientes pasos generales:
- Selección del conjunto de datos, tanto en lo que se refiere a las variables objetivo (aquellas que se quiere predecir, calcular o inferir), como a las variables independientes (las que sirven para hacer el cálculo o proceso), como posiblemente al muestreo de los registros disponibles.
- Análisis de las propiedades de los datos, en especial los histogramas, diagramas de dispersión, presencia de valores atípicos y ausencia de datos (valores nulos).
- Transformación del conjunto de datos de entrada, se realizará de diversas formas en función del análisis previo, con el objetivo de prepararlo para aplicar la técnica de minería de datos que mejor se adapte a los datos y al problema, a este paso también se le conoce como preprocesamiento de los datos.
- Seleccionar y aplicar la técnica de minería de datos, se construye el modelo predictivo, de clasificación o segmentación.
- Extracción de conocimiento, mediante una técnica de minería de datos, se obtiene un modelo de conocimiento, que representa patrones de comportamiento observados en los valores de las variables del problema o relaciones de asociación entre dichas variables. También pueden usarse varias técnicas a la vez para generar distintos modelos, aunque generalmente cada técnica obliga a un preprocesado diferente de los datos.
- Interpretación y evaluación de datos, una vez obtenido el modelo, se debe proceder a su validación comprobando que las conclusiones que arroja son válidas y suficientemente satisfactorias. En el caso de haber obtenido varios modelos mediante el uso de distintas técnicas, se deben comparar los modelos en busca de aquel que se ajuste mejor al problema. Si ninguno de los modelos alcanza los resultados esperados, debe alterarse alguno de los pasos anteriores para generar nuevos modelos.
Si el modelo final no superara esta evaluación el proceso se podría repetir desde el principio o, si el experto lo considera oportuno, a partir de cualquiera de los pasos anteriores. Esta retroalimentación se podrá repetir cuantas veces se considere necesario hasta obtener un modelo válido.
Una vez validado el modelo, si resulta ser aceptable (proporciona salidas adecuadas y/o con márgenes de error admisibles) éste ya está listo para su explotación. Los modelos obtenidos por técnicas de minería de datos se aplican incorporándolos en los sistemas de análisis de información de las organizaciones, e incluso, en los sistemas transaccionales. En este sentido cabe destacar los esfuerzos del Data Mining Group, que está estandarizando el lenguaje PMML (Predictive Model Markup Language), de manera que los modelos de minería de datos sean interoperables en distintas plataformas, con independencia del sistema con el que han sido construidos. Los principales fabricantes de sistemas de bases de datos y programas de análisis de la información hacen uso de este estándar.
Tradicionalmente, las técnicas de minería de datos se aplicaban sobre información contenida en almacenes de datos. De hecho, muchas grandes empresas e instituciones han creado y alimentan bases de datos especialmente diseñadas para proyectos de minería de datos en las que centralizan información potencialmente útil de todas sus áreas de negocio. No obstante, actualmente está cobrando una importancia cada vez mayor la minería de datos desestructurados como información contenida en ficheros de texto, en Internet, etc.
Protocolo de un proyecto de minería de datos
Un proyecto de minería de datos tiene varias fases necesarias que son, esencialmente:
- Comprensión del negocio y del problema que se quiere resolver.
- Determinación, obtención y limpieza de los datos necesarios.
- Creación de modelos matemáticos.
- Validación, comunicación, etc. de los resultados obtenidos.
- Integración, si procede, de los resultados en un sistema transaccional o similar.
La relación entre todas estas fases sólo es lineal sobre el papel. En realidad, es mucho más compleja y esconde toda una jerarquía de subfases. A través de la experiencia acumulada en proyectos de minería de datos se han ido desarrollando metodologías que permiten gestionar esta complejidad de una manera más o menos uniforme.
Técnicas de minería de datos
Como ya se ha comentado, las técnicas de la minería de datos provienen de la Inteligencia artificial y de la estadística, dichas técnicas, no son más que algoritmos, más o menos sofisticados que se aplican sobre un conjunto de datos para obtener unos resultados.
Las técnicas más representativas son:
- Redes neuronales.- Son un paradigma de aprendizaje y procesamiento automático inspirado en la forma en que funciona el sistema nervioso de los animales. Se trata de un sistema de interconexión de neuronas en una red que colabora para producir un estímulo de salida. Algunos ejemplos de red neuronal son:
- El Perceptrón.
- El Perceptrón multicapa.
- Los Mapas Autoorganizados, también conocidos como redes de Kohonen.
- Regresión lineal.- Es la más utilizada para formar relaciones entre datos. Rápida y eficaz pero insuficiente en espacios multidimensionales donde puedan relacionarse más de 2 variables.
- Modelos estadísticos.- Es una expresión simbólica en forma de igualdad o ecuación que se emplea en todos los diseños experimentales y en la regresión para indicar los diferentes factores que modifican la variable de respuesta.
- Reglas de asociación.- Se utilizan para descubrir hechos que ocurren en común dentro de un determinado conjunto de datos.
Según el objetivo del análisis de los datos, los algoritmos utilizados se clasifican en supervisados y no supervisados (Weiss y Indurkhya, 1998):
- Algoritmos supervisados (o predictivos): predicen un dato (o un conjunto de ellos) desconocido a priori, a partir de otros conocidos.
- Algoritmos no supervisados (o del descubrimiento del conocimiento): se descubren patrones y tendencias en los datos.
Ejemplos de uso de la minería de datos
Negocios
La minería de datos puede contribuir significativamente en las aplicaciones de administración empresarial basada en la relación con el cliente. En lugar de contactar con el cliente de forma indiscriminada a través de un centro de llamadas o enviando cartas, sólo se contactará con aquellos que se perciba que tienen una mayor probabilidad de responder positivamente a una determinada oferta o promoción.
Por lo general, las empresas que emplean minería de datos ven rápidamente el retorno de la inversión, pero también reconocen que el número de modelos predictivos desarrollados puede crecer muy rápidamente.
En lugar de crear modelos para predecir qué clientes pueden cambiar, la empresa podría construir modelos separados para cada región y/o para cada tipo de cliente. También puede querer determinar qué clientes van a ser rentables durante una ventana de tiempo (una quincena, un mes, ...) y sólo enviar las ofertas a las personas que es probable que sean rentables. Para mantener esta cantidad de modelos, es necesario gestionar las versiones de cada modelo y pasar a una minería de datos lo más automatizada posible.
Hábitos de compra en supermercados
El ejemplo clásico de aplicación de la minería de datos tiene que ver con la detección de hábitos de compra en supermercados. Un estudio muy citado detectó que los viernes había una cantidad inusualmente elevada de clientes que adquirían a la vez pañales y cerveza. Se detectó que se debía a que dicho día solían acudir al supermercado padres jóvenes cuya perspectiva para el fin de semana consistía en quedarse en casa cuidando de su hijo y viendo la televisión con una cerveza en la mano. El supermercado pudo incrementar sus ventas de cerveza colocándolas próximas a los pañales para fomentar las ventas compulsivas.
Patrones de fuga
Un ejemplo más habitual es el de la detección de patrones de fuga. En muchas industrias —como la banca, las telecomunicaciones, etc.— existe un comprensible interés en detectar cuanto antes aquellos clientes que puedan estar pensando en rescindir sus contratos para, posiblemente, pasarse a la competencia. A estos clientes —y en función de su valor— se les podrían hacer ofertas personalizadas, ofrecer promociones especiales, etc., con el objetivo último de retenerlos. La minería de datos ayuda a determinar qué clientes son los más proclives a darse de baja estudiando sus patrones de comportamiento y comparándolos con muestras de clientes que, efectivamente, se dieron de baja en el pasado.
Fraudes
Un caso análogo es el de la detección de transacciones de lavado de dinero o de fraude en el uso de tarjetas de crédito o de servicios de telefonía móvil e, incluso, en la relación de los contribuyentes con el fisco. Generalmente, estas operaciones fraudulentas o ilegales suelen seguir patrones característicos que permiten, con cierto grado de probabilidad, distinguirlas de las legítimas y desarrollar así mecanismos para tomar medidas rápidas frente a ellas.
Recursos humanos
La minería de datos también puede ser útil para los departamentos de recursos humanos en la identificación de las características de sus empleados de mayor éxito. La información obtenida puede ayudar a la contratación de personal, centrándose en los esfuerzos de sus empleados y los resultados obtenidos por éstos. Además, la ayuda ofrecida por las aplicaciones para Dirección estratégica en una empresa se traducen en la obtención de ventajas a nivel corporativo, tales como mejorar el margen de beneficios o compartir objetivos; y en la mejora de las decisiones operativas, tales como desarrollo de planes de producción o gestión de mano de obra.
Comportamiento en Internet
También es un área en boga el del análisis del comportamiento de los visitantes —sobre todo, cuando son clientes potenciales— en una página de Internet. O la utilización de la información —obtenida por medios más o menos legítimos— sobre ellos para ofrecerles propaganda adaptada específicamente a su perfil. O para, una vez que adquieren un determinado producto, saber inmediatamente qué otro ofrecerle teniendo en cuenta la información histórica disponible acerca de los clientes que han comprado el primero.
Terrorismo
La minería de datos ha sido citada como el método por el cual la unidad Able Danger del Ejército de los EE. UU. había identificado al líder de los atentados del 11 de septiembre de 2001,Mohammed Atta, y a otros tres secuestradores del "11-S" como posibles miembros de una célula de Al Qaeda que operan en los EE. UU. más de un año antes del ataque. Se ha sugerido que tanto la Agencia Central de Inteligencia y su homóloga canadiense, Servicio de Inteligencia y Seguridad Canadiense, también han empleado este método.
Genética
En el estudio de la genética humana, el objetivo principal es entender la relación cartográfica entre las partes y la variación individual en las secuencias del ADN humano y la variabilidad en la susceptibilidad a las enfermedades. En términos más llanos, se trata de saber cómo los cambios en la secuencia de ADN de un individuo afectan al riesgo de desarrollar enfermedades comunes (como por ejemplo el cáncer). Esto es muy importante para ayudar a mejorar el diagnóstico, prevención y tratamiento de las enfermedades. La técnica de minería de datos que se utiliza para realizar esta tarea se conoce como "reducción de dimensionalidad multifactorial".
Ingeniería eléctrica
En el ámbito de la ingeniería eléctrica, las técnicas minería de datos han sido ampliamente utilizadas para monitorizar las condiciones de las instalaciones de alta tensión. La finalidad de esta monitorización es obtener información valiosa sobre el estado del aislamiento de los equipos. Para la vigilancia de las vibraciones o el análisis de los cambios de carga en transformadores se utilizan ciertas técnicas para agrupación de datos (clustering) tales como los Mapas Auto-Organizativos (SOM, Self-organizing map). Estos mapas sirven para detectar condiciones anormales y para estimar la naturaleza de dichas anomalías.
Análisis de gases
También se han aplicado técnicas de minería de datos para el análisis de gases disueltos (DGA, Dissolved gas analysis) en transformadores eléctricos. El análisis de gases disueltos se conoce desde hace mucho tiempo como herramienta para diagnosticar transformadores. Los Mapas Auto-Organizativos (SOM) se utilizan para analizar datos y determinar tendencias que podrían pasarse por alto utilizando las técnicas clásicas DGA.
Tablas
Tabla en las bases de datos, se refiere al tipo de modelado de datos, donde se guardan los datos recogidos por un programa. Su estructura general se asemeja a la vista general de un programa de hoja de cálculo.
Las tablas se componen de dos estructuras:
- Registro: es cada una de las filas en que se divide la tabla. Cada registro contiene datos de los mismos tipos que los demás registros. Ejemplo: en una tabla de nombres y direcciones, cada fila contendrá un nombre y una dirección.
- Campo: es cada una de las columnas que forman la tabla. Contienen datos de tipo diferente a los de otros campos. En el ejemplo anterior, un campo contendrá un tipo de datos único, como una dirección, o un número de teléfono, un nombre, etc.
A los campos se les puede asignar, además, propiedades especiales que afectan a los registros insertados. El campo puede ser definido como índice o autoincrementable, lo cual permite que los datos de ese campo cambien solos o sean el principal indicar a la hora de ordenar los datos contenidos.
Cada tabla creada debe tener un nombre único en la cada Base de Datos, haciéndola accesible mediante su nombre o su seudónimo (Alias) (dependiendo del tipo de base de datos elegida).
La estructura de las tablas viene dado por la forma de un archivo plano, los cuales en un inicio se componían de un modo similar.
Columnas
En el contexto de una tabla de base de datos relacional, una columna es un conjunto de valores de datos de un simple tipo particular, uno por cadafila de la tabla.1 Las columnas proporcionan la estructura según la cual se componen las filas.
El término campo es frecuentemente intercambiable con el de columna, aunque muchos consideran más correcto usar el término campo (o valor de campo) para referirse específicamente al simple elemento que existe en la intersección entre una fila y una columna.
Por ejemplo, una tabla que representa compañías pudo tener las siguientes columnas:
- ID(identificador entero, único a cada fila)
- Nombre (texto)
- Dirección 1 (texto)
- Dirección 2 (texto)
- Ciudad (identificador entero, proviene de una tabla separada de ciudades, de la que cualquier información del estado o del país puede ser tomada)
- Código postal (texto)
- Industria (identificador entero, Proviene de una tabla separada de industrias)
- etc.
Cada fila proporcionaría un valor de los datos para cada columna y después sería entendida como solo simple valor de datos estructurado, en este caso representando a una compañía. Más formalmente, cada fila puede ser interpretada como una variable relacional, compuesta por un conjunto de tuplas, con cada tupla consistiendo en los dos elementos: el nombre de la columna relevante y el valor que esta fila proporciona para esa columna.
| Columna 1 | Columna 2 | |
|---|---|---|
| Fila 1 | Fila 1 Columna 1 | Fila 1 Columna 2 |
| Fila 2 | Fila 2 Columna 1 | Fila 2 Columna 2 |
| Fila 3 | Fila 3 Columna 1 | Fila 3 Columna 2 |
{kind=link}
http://es.wikipedia.org/wiki/Modelo_de_base_de_datos
http://es.wikipedia.org/wiki/Miner%C3%ADa_de_datos
No hay comentarios:
Publicar un comentario